Real Time Data Processing Using Spark Streaming

Objective
A stream of data is nothing but a continuous inflow of data, for example, a live video or Amazon’s log data. There is no discrete start or end to this stream as it keeps flowing forever. Since this stream is continuous, it is also usually high-volume data, which means the size of the incoming data would be large. Data streams are usually processed in near real-time.
Streams are used for the following important reasons:
- They help capture real-time reactions, which can be used for various analytical purposes.
- Since it is near-real-time processing, they can be used for fraud detection or for initiating prompt responses as per the needs of the situation.
- They can be used for scaling up or scaling down hardware as per incoming load.
We have to process the data in micro batches which is a near real time processing. Here, our objective is to create a Spark Streaming application and perform below operations which are handled in near real-time:
- Creation of a Basic Spark Streaming Application
- Different Output Modes
- Triggers
- Transformation
- Joins with Streams
- Window Functions
Prerequisites
- AWS EC2 instance
- NetCat Service
- Basict understanding of AWS
Code Flow
Below is the general code flow of the Spark Streaming application:
1. Create a SparkSession:
Start writing the code by building a SparkSession using the getOrCreate() function:
spark = SparkSession \
.builder \
.appName("StructuredSocketRead") \
.getOrCreate()2. Read from source:
Tell Spark that we would be reading from a socket. Below is the code:
Lines = spark.readStream \
.format("socket") \
.option("host","localhost") \
.option("port",12345).load()3. Start:
Next, we’ll use the writeStream() method and specify the output mode. We’ll also call the start() action at the last. Remember, we need to tell Spark where we want to write our stream to. In our case it is the console. Below is the code line:
query = lines.writeStream \
.outputMode("append") \
.format("console") \
.start()4. AwaitTermination:
At last, we’ll run below code to tell Spark to run continuously until some external termination is called:
query.awaitTermination()Segment 1: A Spark Streaming Application
Let’s first create an application using Spark Streaming which reads data from socket and prints output on console. Below are the steps:
1. Login to Amazon AWS console and launch EC2 instance.

2. Switch to the root user using sudo -i command.
3. Run below commands as root user to install Netcat Service. It is required to open sockets.
yum update -y
yum install -y nc4. Exit from the root user. Let’s create a directory coding_labs and make it current directory using below commands:
mkdir coding_labs
cd mkdir_labs
5. Run the below command to create a file read_from_socket.py:
vi read_from_socket.py
6. Below is the complete code. Hit the ‘I’ key to turn the console into edit mode and paste the below codes to the file. Press ‘Esc’ key and enter :wq! to save the file.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("StructuredSocketRead") \
.getOrCreate()
lines = spark \
.readStream \
.format("socket") \
.option("host","localhost") \
.option("port",12345) \
.load()
query = lines \
.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()
7. As we are reading from a socket, we need to open a socket first. Open another EC2 terminal and allow port 12345 using the below netcat command to communicate with Spark. We’ll send data from this session and Spark will read the input and write the output on the console:
nc -l 12345
8. Switch to the first terminal and Run the application code using below command:
Spark2-submit read_from_socket.py
9. We can see now in below screenshot that spark is waiting for the input stream of data:

10. Let’s write “First Message” on other console and see the result on main console. We can see that the output is printed on another console. Below is the screenshot:

11. Let’s write the “Second Message” and check the output on another console:

Segment 2: Output Modes
The output modes of a streaming query define what DataFrames are to be written to the output sink. There are 3 output modes which are listed below:
- Append : Only modified records are added to the sink.
- Update : Only modified records are added to the sink.
- Complete : All records are added to the sink.
Note: There are, however, a few restrictions on output modes. For example, no aggregations will happen with the update or append mode without watermarks. Also, if there are no aggregations in the streaming, the complete is not supported.
Let’s see how different output modes are implemented in Spark Structured Streaming application.
- Append Mode:
1. Run the below command to create a file stream_output_modes.py:
vi stream_output_modes.py
2. Below is the complete code. Hit the ‘I’ key to turn the console into edit mode and paste the below codes to the file. Press ‘Esc’ key and enter :wq! to save the file. Here output mode is set as append.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("StructuredSocketRead") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN')
lines = spark \
.readStream \
.format("socket") \
.option("host","localhost") \
.option("port",12345) \
.load()
query = lines \
.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()
3. Open another EC2 terminal and allow port 12345 using the below netcat command:
nc -l 123454. Switch to the first terminal and run the application code using below command:
Spark2-submit stream_output_modes.py
5. Let’s write few messages on NetCat console and see the output on other console. Below is the screenshot:

As per the above output, we can see that each input is getting appended as new output with output mode set as append. First, we entered the input “msg1” which came as output in Batch 0. Next, we entered the input “msg2” which was printed in Batch 1. However, at the last, we inserted 2 inputs “msg3” and “msg4”, which are printed together in Batch 2. It shows that append mode is working properly.
- Complete Mode:
1. Run the below command to modify the file stream_output_modes.py:
vi stream_output_modes.py2. Hit the ‘I’ key to turn the console into edit mode and modify the output mode as complete. Press ‘Esc’ key and enter :wq! to save the file. Below is the part of the code which needs to be modified:
query = lines \
.writeStream \
.outputMode("complete") \
.format("console") \
.start()
3. Open another EC2 terminal and allow port 12345 using the below netcat command:
nc -l 123454. Switch to the first terminal and run the application code using below command:
Spark2-submit stream_output_modes.py
5. As I mentioned above that output mode complete is not supported if there are no aggregation in the query. So, our code will not produce any output, rather we’ll get below error:

- Update Mode:
1. Run the below command to modify the file stream_output_modes.py:
vi stream_output_modes.py2. Hit the ‘I’ key to turn the console into edit mode and modify the output mode as update. Press ‘Esc’ key and enter :wq! to save the file. Below is the part of the code which needs to be modified:
query = lines \
.writeStream \
.outputMode("update") \
.format("console") \
.start()
3. Open another EC2 terminal and allow port 12345 using the below netcat command:
nc -l 123454. Switch to the first terminal and run the application code using below command:
Spark2-submit stream_output_modes.py
5. Let’s write few messages on NetCat console and see the output on other console. Below is the screenshot:

As per the above results, we see that we passed 3 separate inputs “new msg”, “second msg” and “Third msg” and updated outputs are getting displayed in Batch 0, 1 and 2 respectively.
Segment 3: Triggers
The trigger settings of a streaming query define the timing of streaming data processing; specifically, whether the query will be executed as a micro-batch query with a fixed batch interval or as a continuous processing query. Triggers are means to decide at what interval new data gets processed in a stream. The default setting would be to do it every time a new micro-batch comes up. We could also do it continuously at each record level or just once for a single micro-batch. Let’s run the query in 2 modes. First, we’ll trigger the query with 2 seconds interval and next we’ll trigger it just once.
- Trigger with 2 seconds:
1. Run the below command to create a file triggers.py:
vi triggers.py2. Below is the section of code which needs to be modified. Hit the ‘I’ key to turn the console into edit mode and paste the below codes to the file. Press ‘Esc’ key and enter :wq! to save the file. Here, we set the processingTime as 2 seconds.
query = lines \
.writeStream \
.outputMode("update") \
.format("console") \
.trigger(processingTime = '2 seconds') \
.start()
3. Open another EC2 terminal and allow port 12345 using the below netcat command:
nc -l 123454. Switch to the first terminal and run the application code using below command:
Spark2-submit triggers.py
5. Let’s provide few inputs with an interval of more than 2 seconds and see the outputs.

As per the above result, we see that output of “first msg”, “second” and “third” are printed in different batches because we entered all the inputs at an interval greater than 2 seconds.
6. Let’s give multiple inputs with an interval less than 2 seconds and see the results.

As mentioned in the above results, we have entered inputs 1, 2, 3 at the same time and result is printed in single batch. In the same way, result of inputs 4, 3, 2 is printed in another single batch.
- Trigger with ‘Once’:
1. Let’s follow the above-mentioned steps and modify the previous code by editing the file triggers.py. Here, allow to trigger the stream only once in query section.
query = lines \
.writeStream \
.outputMode("update") \
.format("console") \
.trigger(once=True) \
.start()
2. Open another EC2 terminal and allow port 12345 using the netcat command.
3. Switch to the first terminal and run the application code using spark2-submit command.
4. Let’s enter an input “message once” and see the output:

We see that after receiving an input once in a single batch, the program exited because it was allowed to receive input batch only once.
Segment 4: Transformations
Spark streaming supports transformation and aggregation as RDD and Dataframes do. Let’s apply a transformation and filter out only those stream inputs which are greater than 4 characters in length. Below are the steps:
1. Run the below command to create a file basic_transform.py:
vi basic_transform.py2. Below is the complete code. Hit the ‘I’ key to turn the console into edit mode and paste the below codes to the file. Press ‘Esc’ key and enter :wq! to save the file. Here, we are importing PySpark SQL functions and creating a transformed Dataframe by applying filter which will allow only those inputs which are greater than 4 characters in length.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
spark = SparkSession \
.builder \
.appName("StructuredSocketRead") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN')
lines = spark \
.readStream \
.format("socket") \
.option("host","localhost") \
.option("port",12345) \
.load()
transformedDF = lines.filter(length(col("value"))>4)
query = transformedDF \
.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()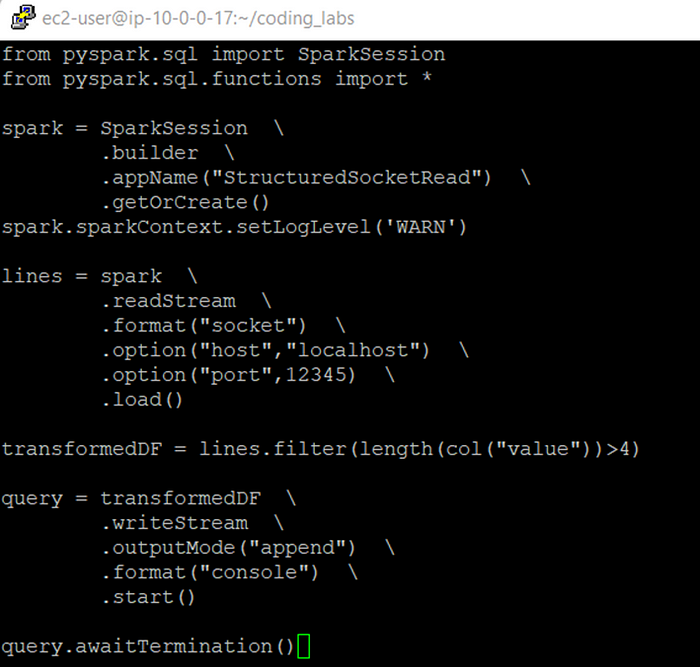
3. Launch another EC2 terminal and open a socket using the below netcat command:
nc -l 123454. Switch to the first terminal and run the application code using below command:
Spark2-submit basic_transform.py
5. Let’s write few messages on socket and see the output on other console. Below is the screenshot:

It is clear from the above result that only those inputs are passed which have length greater than 4 characters.
6. Let’s give more inputs which are less than 4 characters in lengths and see the output.
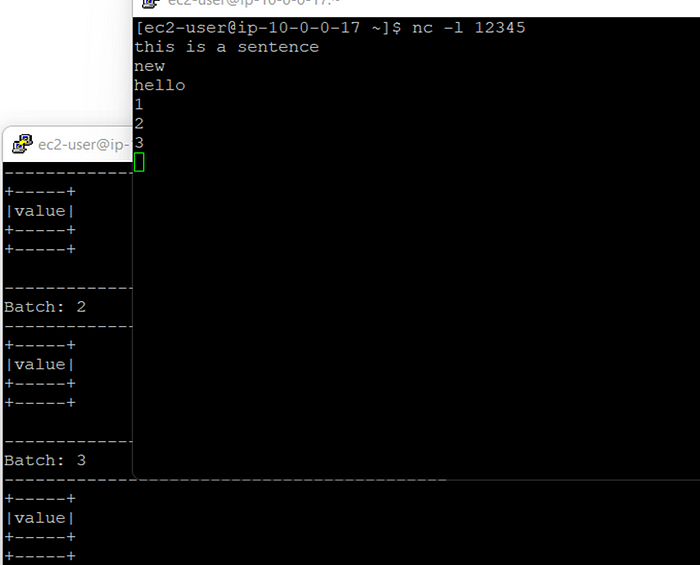
So, we see that there is no output for the inputs “1”, “2” and “3” as their length is less.
Segment 5: Joins with Streams
In a real industry scenario, we may end up in a situation wherein a Spark Structured Streaming application is supposed to process multiple streams of data. In such a situation, one possible operation that we have to apply is to join the different streams into a single one. The primary data structure of a Spark Structured Streaming application is a streaming Dataframe.
Joins in streams is quite similar to the joins in SQL; you only need to assume that each streaming DataFrame is a table. So, stream DataFrames can be joined with other stream or static DataFrames in the same way. Joins are of the following different types:
- Inner Join : Will return records that have matching values in both tables. Outer Join
- Left : Will return all records from the left DataFrame and matching records from the right DataFrame
- Right : Will return all records from the right DataFrame and matching records from the left DataFrame
- Full : Will return all records when there is a match in either the left or the right DataFrame.

There are, however, a few restrictions on outer joins in streams. These include the following:
- Stream-Stream outer joins can be performed only using watermarks.
- Stream-Static right outer or full outer join is not permitted.
- Static-Stream left outer or full outer join is not permitted. The reason for the above restrictions is that we cannot have the entire data of a static DataFrame for a join as it could be a huge load on the system owing to the volume of the data.
Stream-Stream full outer join is not permitted since streams are unbounded and a full outer join would mean putting everything that the stream has ever received. This would again be a huge load on the system. Only append mode is supported for Stream-Stream joins because of the computational restraints as stated above.
Let’s implement Stream-Stream and Static-Stream joins in code.
- Stream-Stream Join:
1. Run the below command to create a file join_stream_stream.py:
vi join_stream_stream.py2. Below is the complete code. Hit the ‘I’ key to turn the console into edit mode and paste the below codes to the file. Press ‘Esc’ key and enter :wq! to save the file. Here, we created two streams and converted them into DataFrames using SelectExpr. The DataFrames had names of players and we performed an inner join on them to see the outputs.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
spark = SparkSession \
.builder \
.appName("StructuredSocketRead") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN')
stream1 = spark \
.readStream \
.format("socket") \
.option("host","localhost") \
.option("port",12345) \
.load()
streamDF1 = stream1.selectExpr("value as player")
stream2 = spark \
.readStream \
.format("socket") \
.option("host","localhost") \
.option("port",12346) \
.load()
streamDF2 = stream2.selectExpr("value as person")
# Inner Join Example
joinedDF = streamDF1.join(streamDF2, expr("""player = person"""))
query = joinedDF \
.writeStream \
.outputMode("append") \
.format("console") \
.start()
query.awaitTermination()
3. Launch 2 new terminals and open 2 sockets to allow ports 12345 and 12346 using below command:
nc -l 12345
nc -l 123464. Switch to the primary terminal and run the application code using below command:
Spark2-submit join_stream_stream.py
5. Let’s give inputs on first socket as “Virat”, “Dhoni” and “Rohit”. on the other socket, let’s give inputs as “Virat” and “Finch”. We’ll see that records are received only for Virat in a single batch on the output console because that is the only value matching in both the streams.
Let’s provide one more input as “Rahul” on both the sockets and see the output. We’ll see that records for Rahul are received on the output console because of matching row in both the streams Dataframes.
Below are the screenshots of the results:

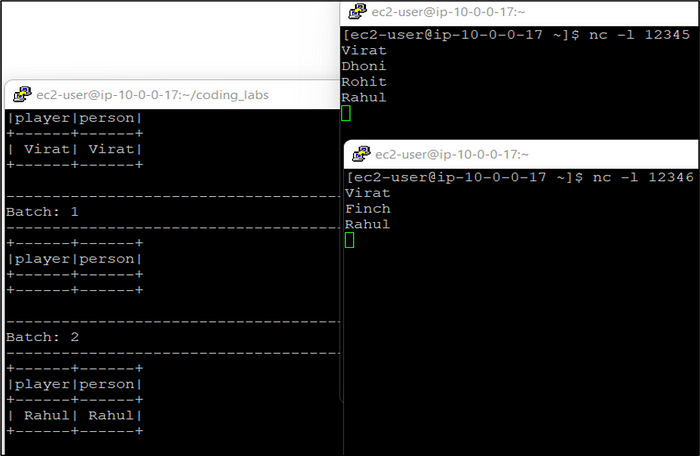
- Static-Stream Join:
1. Run the below command to create a file join_static_stream.py:
vi join_static_stream.py2. Create a static Dataframe players.csv by using vi players.csv command and paste the values for players and their age. Let’s see the contents of the file using below command:
cat players.csv
3. Let’s move this file to the HDFS under a directory called testdir. Below are the commands:
hadoop fs -mkdir testdir
hadoop fs -put players.csv testdir/
4. Below is the section of the code which needs to be modified for the joined. Edit and save the file after pasting the given code.
joinedDF = streamDF.join(staticDF, expr("""player = name"""))
query = joinedDF \
.writeStream \
.outputMode("append") \
.format("console") \
.start()
5. Launch a new terminal and open a socket for the port 12345 using netcat command.
6. Switch to the primary terminal and run the application code using below command:
Spark2-submit join_stream_stream.py7. Start sending message in the stream. We have name from the stream Dataframe and we’ll receive age from the static Dataframe. Below is the screenshot:

As per the above result, we can understand that for the input value “virat”, we received the age from the static Dataframe because “virat” is available in both the Dataframes. However, for the input value “finch” there is no output as this record is not present in static Dataframe.
8. Let’s change our code and apply Left Outer join by modifying below section and run the application again.
joinedDF = streamDF.join(staticDF, expr("""player = name"""), "left_outer")
query = joinedDF \
.writeStream \
.outputMode("append") \
.format("console") \
.start()
9. Let’s enter 2 inputs “virat” and “finch” this time and see the output. Below is the screenshot:

We see that this time, we have received output for “finch” as well but age and name fields are null due to Left Join.
Segment 6: Windows in Spark Streaming
In an application that process real-time events, it is common to perform some set-based computation (aggregation) or other operations on subsets of events that fall within some period of time. Since the concept of time is a fundamental necessity to complex event-processing systems, it is important to have a simple way to work with the time component of query logic in the system. Below are the 2 points which we should understand in refence of time:
- Event Time : It is the time when the record is generated at the source. It is generally represented as a column in the source data set.
- Processing Time : It is the time when the record arrives at the Spark processing layer. The difference between the event time and the processing time is due to various reasons such as publishing failures, distributed system lags, network delays and other such latencies. A window is nothing but a collection of records over a specific time period. There are 2 types windows in Spark Streaming:
- Tumbling Window : No two windows overlap.
- Sliding Window : Windows may or may not overlap.
The sliding duration in the former is equal to the window duration, which ensures that no two windows are overlapping. In the latter, the window duration is always a multiple of the sliding duration, thereby causing the overlap.

Let’s implement the window in our code and see the results.
1. Run the below command to create a file window_functions.py:
vi window_functions.py
2. Below is the complete code. Paste it to the above created file and save it. Here, we have created a schema with activity_type, activity_time and activity_count. Also, we set a window duration of 1 day, while our sliding duration is set to 1 hour. As we are using aggregations, we have changed our output mode to Complete.
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
spark = SparkSession \
.builder \
.appName("StructuredSocketRead") \
.getOrCreate()
spark.sparkContext.setLogLevel('WARN')
mySchema = StructType().add("activity_type", "string").add("activity_time","timestamp").add("activity_count","integer")
lines = spark \
.readStream \
.schema(mySchema) \
.json("data/")
windowDF = lines.groupBy(window("activity_time","1 day","1 hour")).sum("activity_count").alias("Events_Sum").orderBy(asc("window"))
query = windowDF \
.writeStream \
.outputMode("complete") \
.format("console") \
.option("truncate", "False") \
.option("numRows",200) \
.start()
query.awaitTermination()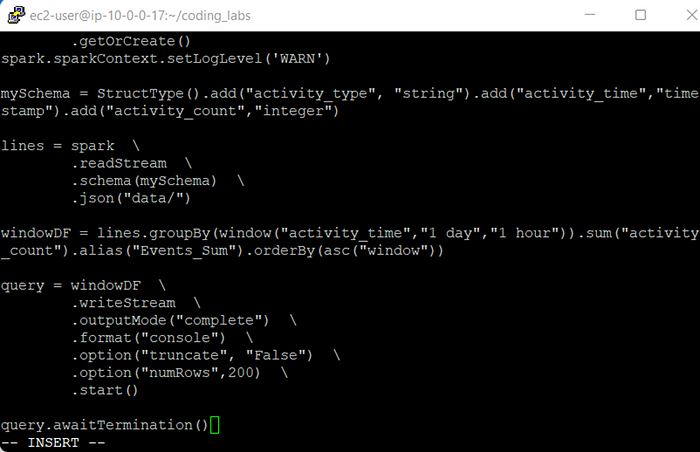
3. Run the below command to create a log.json file:
vi log.json
4. Paste below json text in the above file and save it. This data represents a system log where activity_type shows CPU/Memory utilization, IO or network issue. The activity_time shows timestamp of the event happened and activity_count talks about total number of events happened on a particular timestamp.
{"activity_type":"CPU","activity_time":"2020-08-15T05:34:45","activity_count":5},
{"activity_type":"Memory","activity_time":"2020-08-15T05:48:05","activity_count":2},
{"activity_type":"CPU","activity_time":"2020-08-15T05:54:41","activity_count":8},
{"activity_type":"IO","activity_time":"2020-08-15T06:32:45","activity_count":3},
{"activity_type":"Network","activity_time":"2020-08-15T06:46:05","activity_count":12},
{"activity_type":"CPU","activity_time":"2020-08-15T06:53:41","activity_count":16},
{"activity_type":"CPU","activity_time":"2020-08-15T09:30:45","activity_count":4},
{"activity_type":"IO","activity_time":"2020-08-15T09:48:05","activity_count":1},
{"activity_type":"Network","activity_time":"2020-08-15T10:44:41","activity_count":9},
{"activity_type":"CPU","activity_time":"2020-08-15T11:34:45","activity_count":5},
{"activity_type":"Network","activity_time":"2020-08-15T11:48:05","activity_count":3},
{"activity_type":"Memory","activity_time":"2020-08-17T20:54:41","activity_count":6},
{"activity_type":"CPU","activity_time":"2020-08-17T21:34:45","activity_count":9},
{"activity_type":"IO","activity_time":"2020-08-17T21:48:05","activity_count":3},
{"activity_type":"IO","activity_time":"2020-08-18T05:54:41","activity_count":6},
{"activity_type":"Network","activity_time":"2020-08-19T15:34:45","activity_count":5},
{"activity_type":"Memory","activity_time":"2020-08-19T15:48:05","activity_count":7},
{"activity_type":"CPU","activity_time":"2020-08-19T17:04:41","activity_count":3},
{"activity_type":"Network","activity_time":"2020-08-19T17:04:45","activity_count":6},
{"activity_type":"Memory","activity_time":"2020-08-19T17:08:05","activity_count":2},
{"activity_type":"CPU","activity_time":"2020-08-19T18:44:41","activity_count":4},
{"activity_type":"Network","activity_time":"2020-08-20T07:14:15","activity_count":5},
{"activity_type":"IO","activity_time":"2020-08-20T07:18:15","activity_count":6},
{"activity_type":"CPU","activity_time":"2020-08-20T07:34:01","activity_count":1}
5. Create a directory data in HDFS and move the log.json file inside this folder. Below is the screenshot:

6. Create a file input1.csv by picking some records from the log.json file to implement the window function. We have taken top 3 records which are shown below:

{"activity_type":"CPU","activity_time":"2020-08-15T05:34:45","activity_count":5},
{"activity_type":"Memory","activity_time":"2020-08-15T05:48:05","activity_count":2},
{"activity_type":"CPU","activity_time":"2020-08-15T05:54:41","activity_count":8}7. Let’s move this input1.csv file to the hdfs location by using below commands:
hadoop fs -put input1.csv data/8. Switch to the primary terminal and run the application programme using below command:
Spark2-submit window_functions.py
9. Let’s observe the output. Here, we see that our output shows each record with a window of 24 hours (Aug 14th — Aug 15th and Aug 15th — Aug 16th) and sliding window of 1 hour. It shows total event counts at each 1-hour interval. Below is the screenshot:

Conclusion
Spark Streaming comes with plenty of feature. We were able to learn and implemented different streaming operations. Below are few points:
- Used Spark Structured Streaming API in our case study to build an application to consume streaming data from socket and write output to the console.
- Learnt about Triggers and various Output Modes and implemented in application.
- Next, we implemented a Transformation in the code and observed results.
- Also, learnt about Event Time and Processing Time followed by the concepts of Windows.
- Understood the difference between Sliding and Tumbling Windows.
- Implemented a Window function with window duration of 1 day and sliding duration of 1 hour.
